
To start with, here is Wikipedia's short introduction to genetics, along with a diagram from the Human Genome Project's piece on basic genetics. So, every organism on earth has a genome, a very long string of genetic information. In all but some viruses, the information is carried in a molecule called DNA, which consists of two 'spines' twisted together and linked by pairs of simpler molecules called 'bases', making something like a giant rope ladder twisted around into a spiral (diagram below thanks to www.chemguide.co.uk). There are only four options (given the letters G, C, A and T) for these bases, so the complete DNA sequence is a long (around three billion letters long in humans!) string of letters: GCCATCGTTCAATACGCC and so on.
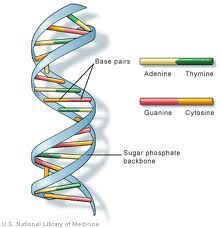
Some sections of the DNA sequence, the string of letters, cause proteins to be made. Proteins are the chemicals that form the basis of pretty much everything in any living being; skin, blood, nerves, muscle and much more. In the protein-making sections of the DNA sequence, each little group of three letters gives an instruction for a certain protein component (called an amino acid) to be made. Large parts of the DNA sequence, though, don't seem to do much; a point which I'll come back to later.
On to Francis Collins' book, then. Starting on page 126, he notes that our DNA has much in common with the DNA of other creatures, especially mammals but also fish and even some insects. The amount in common changes quite a lot depending on whether you're looking at parts of the human DNA sequence that code for proteins or at the other, apparently inactive parts (so-called junk DNA). If you start with a stretch of human DNA in a protein-coding area, the chances of finding a similar sequence in other creatures are:
Chimpanzee 100%
Dog 99%
Mouse 99%
Chicken 75%
Fruit fly 60%
Roundworm 35%
But the chances of a close match drop quite a bit if you look at those 'junk' DNA sections:
Chimpanzee 98%
Dog 52%
Mouse 40%
Chicken 4%
Fruit fly almost 0%
Roundworm almost 0%
Doesn't this strike you as odd? Why should the correlation between human and other DNA be much higher in the protein-coding areas than in 'junk' DNA? Collins says it gives support in two ways for an evolutionary understanding of how we came to be. Firstly (from page 129), he notes that we can build up a tree of organisms that shows how closely related they are, based on how much DNA they have in common:
At the level of the genome as a whole, a computer can construct a tree of life based solely upon the similarities of the DNA sequences of multiple organisms... Bear in mind that this analysis does not utilize any information from the fossil record, or from anatomic observation of current life forms. Yet its similarity to conclusions drawn from studies of comparative anatomy, both of existent organisms and of fossilized remains, is striking.
The second point Collins makes is that evolutionary theory predicts a gradual build-up of mutations that do not affect the organism, while mutations that do have an effect will be much rarer. And this is what we see; mutations in the 'junk' DNA sections are far more common than mutations in areas that give instructions for making proteins. This is because most of the latter will severely hamper the individual organism in which they happen, leading to the organism probably not surviving to adulthood and therefore not having any offspring to pass the mutation on to. Only a few mutations in protein-coding areas will be advantageous (or at least neutral) to the organism and stand a chance of being passed on to the next generation.
There's a follow-up to the second point, which relates to the fact that a few DNA mutations don't lead to the protein changing. As I mentioned above, the DNA sequence is basically made up of a huge string of the letters G, C, A and T. In sections of the DNA that cause proteins to be made, each set of three letters gives an instruction for a certain protein component (called an amino acid) to be made. For most of these protein components the set of three letters has to be exactly right, but there are a few where changing one letter in the set for a different letter still leads to the same amino acid being made. And these 'silent' mutations are seen far more often than mutations that do cause a different protein component to be made. I wonder why this might be, if not because evolution is the means by which humanity was created...






Are you saying that Collins says that in the protein coding sections of our DNA that humans and chimps are 100% identical? That doesn't seem right given how different we are. I suspect, but don't know, that maybe something has been lost in the translation from Collins.????
ReplyDeleteNot sure, sorry - Collins did say similar sequence, not identical sequence. Perhaps that's it?
ReplyDeleteQuite right, I misread. My mistake. I should have looked at it more carefully.
ReplyDelete